I am pretty fast at typing.
I am by no means the fastest ever, but I can hold my own.
I don’t really worry about how fast I can type,
but I do slightly worry about repetitive strain injuries.
Therefore, I have allowed myself to be distracted from learning to read faster.
I have been playing around (yet again) with learning the Dvorak Simplified Keyboard layout,
and I am (still) convinced that it is dramatically better than the traditional QWERTY layout.
The Dvorak layout is basically a keyboard layout that makes sense.
Instead of the letters and symbols being more or less randomly placed as in the common QWERTY layout,
the keyboard is laid out keeping two goals in mind:
- Frequently used keys should be easier to reach with the stronger fingers (e.g. not the pinky).
- Keys that are frequently pressed sequentually (e.g. consonants are usually followed by a vowel and vice versa) should be pressed by opposite hands.
These two goals make everything ergonomic and efficient.
If you would like more details, then I strongly suggest you read this comic about it.
It is very informative and mildly entertaining and by the end of it you may share my opinion of the superiority of Dvorak.
Or you may not.
But you should still read it.
Of course, you can always find more detail in the wikipedia entry.
Despite it’s rationality, learning the Dvorak layout is difficult.
I have spent a considerable amount of time on it at one point or another,
but I have spent almost 20 years learning the normal layout…
This makes it difficult for me to switch over to Dvorak completely,
which is what I would need to do in order to really get good at it.
This isn’t the first time I’ve tried.
In fact, the das keyboards that I normally use (yes, I have two),
I selected with alternative keyboard layouts in mind.
There are no markings on the keyboard,
so I feel like it doesn’t matter as much that I keep the QWERTY layout.
Even with prior practice, it is very hard to type at half speed during my everyday tasks. To illustrate, I’ll show you some of my results from typeracer.com (which is awesome). This is how fast I type normally:
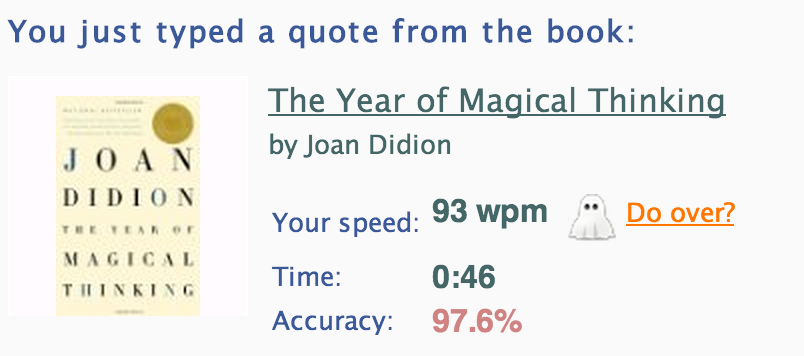
And this is how fast I type with Dvorak:

If you can imagine with me,
typing with Dvorak basically feels like one of those dreams where you are trying to escape bigfoot,
but you can’t run any faster than slow motion.
It’s slightly depressing.
It gets worse.
Shortcut keys.
You have to develop completely new habits of using shortcut keys.
Control-c for copying and control-v for pasting are no longer right next to each other.
You could remap them, but I would not recommend it.
Most shortcut keys start with letters for the thing you want to do (e.g. c for copy),
so it’s not too hard to remember them.
It’s just hard to develop the new habits.
Furthermore, all of the symbols ((), [], +, =, etc.) are in different locations,
and, since I don’t type most of those very often,
they are more difficult to learn.
Coding is especially difficult.
Coding is just typing, after all.
Unfortunately, coding does slow my typing down,
and when I’m using Dvorak it’s even worse.
As evidence, I’ll show you some test results from typing.io,
which has typing tests with real code and is also awesome. Here is normal layout:

And this is with Dvorak:

As you can see, slightly depressing.
In order to improve the situation,
I thought it would be good to find a layout that put the commonly used coding symbols within easy reach.
I did find such a layout.
It’s called Programmer Dvorak Keyboard Layout.
Don’t use it.
I abandoned it for a couple of reasons.
First of all, it rearranges all of the numbers.
Why? I’m not sure (I guess the Dvorak layout normally had them arranged that way),
but it makes it incredibly confusing because instead of 1, 2, 3 we now have 7, 5, 3…
Not only that, but it puts the numbers in a shift position!
So, to type a 7, I have to press shift and what used to be the 2 key.
This was the deal breaker for me.
All keyboard shortcuts that included a number were unusable for me on my Mac.
I literally could not do the shortcut because command-shift-4 (for example) is its own shortcut combo.
So, I am still learning the Dvorak layout, but it’s hard.
I was originally going to write this post using it,
but by the time I had done the typing tests,
I figured I didn’t want to waste the time.
It has taken me a while to get up around 40 wpm,
but not as long as I thought — probably a week for the initial learning and then a couple of weeks to improve speed.
I plan on continuing to get faster at it here and there,
and hopefully I can replace QWERTY completely one day.
Because I really do believe in it.




